3FS是幻方AI自研的高速文件系统,是幻方“萤火二号”计算存储分离后,存储服务中的重要一环,全称是萤火文件系统(Fire-Flyer File System),因为有三个连续的 F,念起来不是很容易,因此被简称为 3FS。
3FS 是一个比较特殊的文件系统,因为它几乎只用在AI训练时计算节点中的模型批量读取样本数据这个场景上,通过高速的计算存储交互加快模型训练。这是一个大规模的随机读取任务,而且读上来的数据不会在短时间内再次被用到,因此我们无法使用“读取缓存”这一最重要的工具来优化文件读取,即使是超前读取也是毫无用武之地。 因此,3FS的实现也和其他文件系统有着比较大的区别。
本期文章将为大家解密幻方AI是如何设计与实现3FS的,以及最终能实现的模型训练加速效果。
硬件设计
3FS文件系统整体的硬件设计如下图展示:

可以看到,3FS文件系统包含两大部分:数据存储服务与高速交换机。数据存储服务与计算节点分离,专门用于存储模型训练需要用到的样本数据。每个存储服务节点有16张各15TB的SSD硬盘和2张高速网卡,读取性能强劲,网络宽带强大。
3FS节点与计算节点(Clients)通过800口高速交换机进行连接。值得注意的是,因为一台交换机要连接 600 台左右的计算节点,每个计算节点就只能使用一张网卡,这样,从3FS上读取样本数据的流量和训练产生的其他数据流量(梯度信息、数据并行信息等)就不得不分享这一张网卡的带宽,这对3FS整体读取性能带来了一些挑战。
软件实现
前文中提到,3FS解决的是模型训练中样本数据读取这个特定的使用场景。与常见的文件读取方式不同,训练需要读取的样本是随机的,而且往往一个batch里用到的是互不相关的样本。注意到这一点后,我们决定设计异步的文件读取方式。
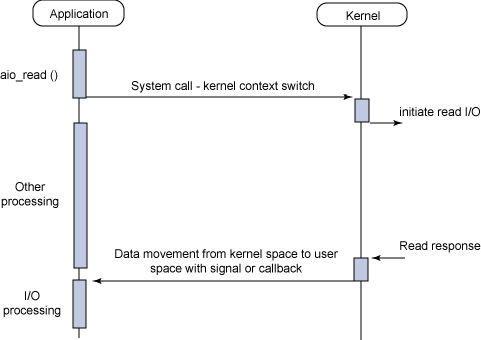
具体的,如上图所示,3FS使用基于Linux的 AIO 和 io_uring 接口来完成样本的读取,因为在3FS的场景下,File Cache 完全没有作用,反而会以一种用户很难控制的方式消耗系统的内存,影响后续任务的运行,因此我们关闭了 File Cache,只用 Direct I/O 模式做数据的读取。但要注意的是,用这种方式读取,buffer 指针,offset 和长度都是需要对齐的,如果让用户来做这个对齐,就会产生额外的内存拷贝,因此我们在文件系统内部把对齐做掉了,既优化了性能又方便了用户。
用户使用3FS非常简单,只需要将样本数据转化成FFRecord格式,存入3FS中即可。FFRecord格式是幻方AI开发的一种适用于3FS性能的二进制序列存储格式,适配了 PyTorch 的 Dataset 和 Dataloader 接口,可以非常方便的加载发起训练。具体项目地址: https://github.com/HFAiLab/ffrecord
在使用幻方萤火进行模型训练时,只需要将原始数据做完特征工程,转化成输入模型的样本数据,通过3FS加载,你就可以享受到极致的存储性能体验。
压力测试
幻方萤火二号目前有64台存储服务器构成3FS文件系统。想象一下,训练一个 ResNet,读取 ImageNet 数据,ImageNet 压缩文件大小148G,解压整理成 FFRecord 格式的二进制训练样本数据有700G+,假设 batch_size 为400读满单个A100 40G显存,使用3FS读取数据在最优性能下每 Epoch 读取 ImageNet 数据只需耗时0.29s~0.10s左右。这极大降低数据加载的开销,充分利用GPU的计算时间,提高GPU利用率。

上图展示了分布式训练 ResNet 实际每轮 Epoch 耗时情况。可以看到,即使在集群满负荷状态下,读取数据的耗时仅占总耗时的1.8%左右,具有相当不错的数据读取性能。