全世界都在给 GPT 的训练和推理算账,以至于微软会迫不及待地分享“每美元的推理能获得 2 倍的性能”的喜讯,其传递的信号或许是:一丁点的算力浪费,都在这场 AI 竞争里是致命的。
而越往后发展,模型训练效率的高低,越发成为科研人员不容忽视的难点。无论从加快训练测试更多参数,还是从节省研发成本的角度来说,低效的任务训练已经变得不可容忍。摆在眼前的,对于科研用户来说,一套趁手易用的模型性能分析工具,是工作中的必备利器。那么如何快速得给模型做一个全方位的“体检”,如何更简单高效的地定位模型训练中的“病灶”?今天就为大家介绍幻方 AI 研发的模型性能分析工具 haiprof。
haiprof
haiprof (High-flyer’s AI Profile) 是一个针对 PyTorch 模型的性能分析工具,用户能够在无需修改代码的情况下分析模型性能瓶颈。在任务运行的过程中,haiprof 会收集以下信息:
- CPU/GPU 利用率、功率、内存占用
- 用户读写流量、IB 流量
- 内存带宽、跨 NUMA 带宽
- forward、backward、optimizer、dataloader 的耗时
haiprof 还支持对 PyTorch 代码进行更深入的 tracing,分析不同函数、算子的时间开销。
使用方式如下:
hai python train.py -- --nodes 8 --options profile.time=120 --options profile.trace=1
haiprof train.py --time 120先提交任务,后开启分析工具。接下来我们将会以一个真实场景下,用户模型训练的优化过程作为示例,来演示 haiprof 的使用方法。
模型运行全景 profile 请求
1. 查看任务Log
这是一个正在运行的训练任务的日志,在日志中我们打印出了每个 step 的 forward、backward 耗时。我们可以看到,这个任务的 forward 耗时要远远大于 backward 。通常来说,大部分模型的 forward 时间和 backward 是差不多或者更小的。这个训练任务显然存在着一些问题。接下来我们用 haiprof 分析一下该模型。

2. 使用 haiprof 命令行工具
这里我们先使用 hfai prof 命令工具对正在运行中的任务做一个简单的 profile,使用上只需要指定任务的 ID 或者名字,然后设置 profile 的时长。
haiprof train.py –time 60现在我们成功提交了对 train.py 这个任务的 profile 请求,然后我们需要等待 60 秒,profile 完成后会把结果写入 log 文件夹。接下来我们可以使用 haiprof 提供的可视化工具进行分析。
3. 运行数据可视化分析
我们在 haiprof 库提供了一个 Analyzer 工具,用户只需要输入 profile 的 log 文件夹路径即可。
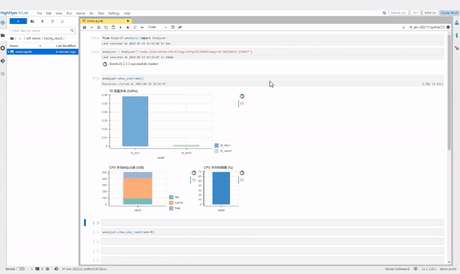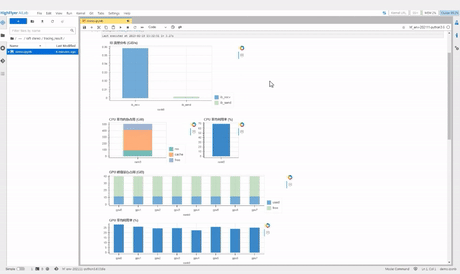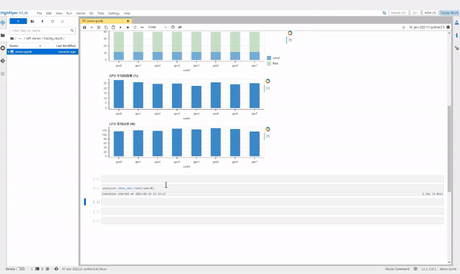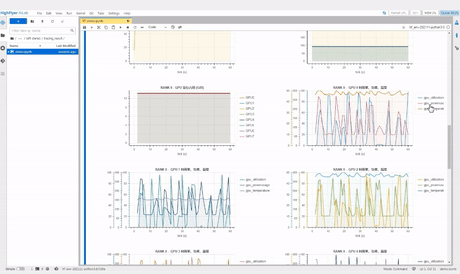
我们先调用 show_overview 函数来看看任务的整体运行情况

从上图中我们可以看到整个任务的 IB 平均流量、 CPU、GPU 平均利用率,以及内存、显存的占用情况等等。我们观察到这个训练任务的 GPU 利用率非常低,只有 30%,而 CPU 利用率却有 60%~70%。
接下来我们通过 show_one_rank 函数来看看详细的情况

这里我们看到 GPU 的利用率时高时低,有一半的时间的利用率都接近 0。
由此我们可以推测该训练任务阻塞在 CPU 运算上。
任务毫秒级 tracing
1. 使用 haiprof 命令行工具
为了更详细地分析模型的运行时间,我们可以使用 haiprof 的 tracing 功能,用户只需要在使用 hai python 提交任务的时候指定选项 profile.trace=1,就可以自动地对任务进行毫秒级别的 tracing。
hai python train.py -n 1 -p 50-f –opons profile.trace=1 –options profile.warmup=120 –options profile.time=15该命令代表先预热 120 秒,然后 tracing 15 秒
2. 运行数据可视化分析
Tracing 结束后结果以 json 格式保存在 log 目录里。我们可以把结果拷贝到当前目录然后使用 tensorboard 查看结果:
打开 tensorboard,在 overview 页面我们可以看到模型运行过程中的 GPU SM 利用率、不同部分的时间占比等。

在 GPU kernel 页面我们可以看到不同 GPU kernel 算子的时间占比。

在 trace 页面,我们可以看到整个模型运行的 timeline,里面包括的 forward、backward、optimizer 的时间,以及不同算子、函数的时间占比。

这里我们看到,这个模型中有相当一部分的算子运算是在 CPU 上做的,这导致了在大部分的时间 GPU 都处于空闲状态。
诊断后优化
接下来我们根据这个发现优化一下模型,把这部分算子放到 GPU 上计算。改完后重新提交任务:
hai python train.py -n 1 -p 50 -f –name v2我们可以看到,优化过后的模型 forward 的时间只有原来的 1/3,整体训练速度提升了一倍。
