用 AI 方法对现代数值天气预报(numerical weather prediction, NWP)进行改进提升近两年受到了广泛关注,如 Nvidia 发布的 FourCastNet、 DeepMind 发布的 GraphCast 和华为发布的盘古气象大模型,在与欧洲中期天气预报中心(ECMWF)的高分辨率综合预测系统(IFS)对比中都获得了不错的效果。
基于此,我们最近复现整合了这些工作,并将这些成果贡献给开源社区。我们基于 FourCastNet 和 GraphCast 论文构建了一个新的全球AI气象预测项目 —— OpenCastKit。

项目地址:https://github.com/HFAiLab/OpenCastKit
这个项目提供了一个强大的、基于ERA5数据训练的开源气象模型和参数,可以生成全球高分辨率的气象预测。具体来说,它包含:
- 一个统一的数据处理工具,抽取ERA5数据和特征并整理成高性能训练数据格式 FFRecord;
- 基于 hfai 算子和 hfreduce 并行通信优化的 FourCastNet 模型源码和 GraphCast 模型源码,供社区研究优化;
- 基于1979年到2022年15TB的ERA5数据,在萤火高性能集群上训练的模型参数,可以进行微调,获得高精度预测结果。
同时,我们上线了一个每日更新的 HF-Earth,实时展示气象大模型输出的全球预报效果:

Demo地址:https://www.high-flyer.cn/hf-earth/
经过一段时间的测试来看,AI气象大模型对台风、极端降水等事件的预测上效果明显,在长期气候变化的分析中可以起到一定作用。希望在此开源项目的基础上,构建出更加强大的 AI 气象应用。
数据集
欧洲中期天气预报中心(ECMWF)提供了一个公开可用的综合数据集 ERA5,其将物理模型数据与来自世界各地的观测数据结合起来,形成一个全球完整的、一致的数据集,以小时级到天级不等,提供包括温度、风量、降水、水文、气压等多项全球气象指标数据,供各种气象预报模型学习。
官方地址:https://www.ecmwf.int/en/forecasts/datasets/reanalysis-datasets/era5
FourCastNet 与 GraphCast 使用了不同规模的 ERA5 数据来训练,产生的预测效果各自不同。前者仅使用了 20 个相关气象指标,包括 4 个不同位势高度下的温度、风速、相对湿度和一些近地表变量,其旨对极端天气、自然灾害进行预警;而后者使用了更加全面的数据,其包含 37 个不同位势高度下的气象指标和 5 个地表气象指标,总计 227 个指标,其旨在对气象变化进行更加全面的评估和预报。
对此,我们将这些数据进行了归纳整理,通过 hfai.datasets 工具进行管理优化。原始数据通过特征处理,转化成 “” 的模式,通过高性能训练样本格式 ffrecord 进行保存,从而可以在萤火集群中进行高效的并行训练。更多信息可以浏览 hfai 数据集仓库。
模型构建和优化
为了进行 0.25° 分辨率下的全球气象预测,FourCastNet 采用自适应傅里叶神经算子 AFNO,而 GraphCast 采用了图神经网络。前者计算效率高效,可以灵活且可扩展地建模跨空间和不同指标之间的依赖关系;后者通过构建节点之间的联系,更加详细捕捉如“蝴蝶效应”般的气候因子影响。前者在小 batchsize 上可以进行数据并行以加速训练,而后者球体节点之间的 message passing 参数规模更大,需要进行流水线并行(或称模型并行)的改造,以实现模型的完整训练。


这里我们采用自研的 haiscale 高性能并行训练工具库对两种模型进行复现优化。对于 FourCastNet,我们使用 haiscale.ddp 或者 haiscale.fsdp 进行数据并行优化,实验中我们采用小 batchsize 即实现了论文效果的复现;对于 GraphCast,完整参数基本无法塞入单张显卡,因此对于不同的环节,如球体中 grid 节点与 mesh 节点进行message passing,我们需要对其拆分,让其分布在不同的显卡上,通过 haiscale.pipeline 对不同环节进行串联,实现模型并行训练。具体如下:
FourCastNet 数据并行
FourCastNet 模型的训练包括 pretrian、finetune 和 precipitation 三个部分。模型采用递进式,即以 作为输入,预测下一步 。一次训练输出多步,与真值对比计算 loss。如下伪代码所示:
from hfai.datasets import ERA5
from haiscale.ddp import DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
model = FourCastNet(args).cuda()
model = DistributedDataParallel(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
data = ERA5(split='train')
sampler = DistributedSamper(data, shuffle=True)
dataloader = data.loader(args.batch_szie, sampler=sampler, num_workers=8, pin_memory=True, drop_last=True)
# training ...
for step, (xt0, xt1, xt2, pt2) in enumerate(dataloader):
xt1_pred = model(xt0) # pretrain
xt2_pred = model(xt1_pred) # finetune
pt2_pred = model(xt2_pred, precip=True) # preciptation
pretrain_loss = criterion(xt1_pred, xt1)
finttune_loss = criterion(xt2_pred, xt2)
precip_loss = criterion(pt2_pred, pt2)
# optim ...
# stop hfreduce
model.reducer.stop()haiscale.ddp 默认采用 hfreduce 进行通信优化,我们还可以使用优化算子,加入一行 model = hfai.nn.to_hfai(model) 代码进行进一步加速。在萤火集群上我们使用 96 张 A100 进行数据并行加速,耗时 16~17 个小时左右基本可以完成 FourCastNet 的整体训练。
GraphCast 数据并行
不同于 FourCastNet,GraphCast 只有主干模型一个,其也是采用递进式,不过以 作为输入,预测下一步 。这里 代表了时间戳信息和地理位置信息, 代表所构建的球体 Graph 信息。如下伪代码所示:
from hfai.datasets import ERA5
from haiscale.ddp import DistributedDataParallel
from haiscale.pipeline import PipeDream, make_subgroups, partition
from torch.utils.data.distributed import DistributedSampler
dist.init_process_group(...)
torch.cuda.set_device(local_rank)
rank, world_size = dist.get_rank(), dist.get_world_size()
dp_group, pp_group = make_subgroups(pp_size=pp_size)
dp_rank, dp_size = dp_group.rank(), dp_group.size()
pp_rank, pp_size = pp_group.rank(), pp_group.size()
model = GraphCast_sequentail(args)
model = partition(model, pp_group.rank(), pp_group.size(), balance=[1,1,1,1,1,1,1,1])
model = DistributedDataParallel(model.cuda(), process_group=dp_group)
model = PipeDream(model, args.chunks, process_group=pp_group)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
data = ERA5(split='train')
sampler = DistributedSamper(data, num_replicas=dp_size, rank=dp_rank, shuffle=True)
dataloader = data.loader(args.batch_szie, sampler=sampler, num_workers=8, pin_memory=True, drop_last=True)
earth_graph = generate_graph(args)
# training ...
for step, (xt0, xt1, xt2) in enumerate(dataloader):
loss = model.forward_backward(xt0, xt1, earth_graph, criterion=criterion, labels=(xt2,))
# optim ...
# synchronize all processes
model.module.reducer.stop()
dist.barrier()在使用 haiscale.pipeline 进行流水线并行训练时,需要我们提前将模型进行拆分,通过 haiscale.SequentialModel 进行模型的串联。同时 haiscale 提供了一个统一的 forward_backward 接口,进行样本和标签的统一输入和结果输出。在萤火集群上我们使用 256 张 A100 进行模型并行加速(单节点 8 卡做流水并行,32 节点做数据并行),耗时 3 天左右基本可以完成 GraphCast 的整体训练。
关于代码的更多细节可以访问项目地址阅读源码。
预测结果
参照论文中的评估方式,我们采用递归输出未来多天的预测结果,与真实值对比,通过误差增长曲线来比较不同AI气象大模型的预测效果。如下图所示:

可以看到,在进行 14 天的中期天气预报测试中,无论是GraphCast 还是 FourCastNet,递归预测导致误差随时间逐步增长。整体误差上看 GraphCast 考虑了地理时间和地理位置的因素,预测误差比 FourCastNet 要小。受此启发,我们将时间和地理信息加入 FourCastNet 进行模型训练(FourCastNet+),发现最终模型输出的预测误差几乎与 GraphCast 一致。
下面我们以 2022 年 6 月 22 日开始连续输出 14 天的预测,展示 OpenCastKit 的预测效果:
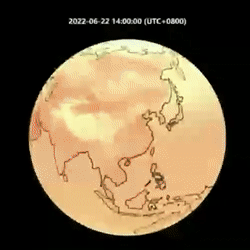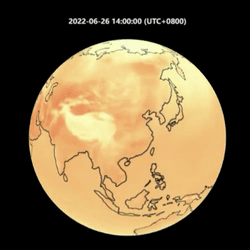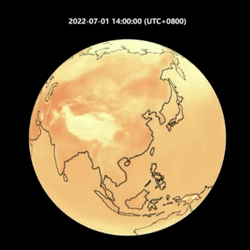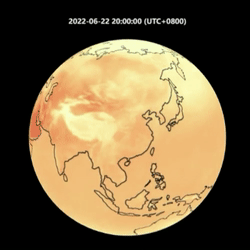

FourCastNet 温度预测与风力预测


GraphCast 温度预测与风力预测


真实温度与风力
可以看到 FourCastNet 和 GraphCast 都可以对风力和温度的衍变进行比较准确的预测。其中 GraphCast 相对来说更加接近真实情况,包括气象指标的细节纹理更丰富和一致,还有在6月30号开始在我国东南沿海的两次台风路径的预测。